Índice
- Descrição do problema
- Tipo de problema
- Seleção das variáveis
- Tipo de modelo
- Modelagem
- Performance do Modelo
- Importância das variáveis (Feature Importance)
Descrição do problema:

É possível realizar um diagnóstico hipotético do autismo apenas utilizando traços comportamentais?
O Transtorno do Espectro Autista é uma condição neurológica que se caracteriza por traços comportamentais nos quais a dificuldade de se relacionar socialmente se mostra frequente e há a presença de outros comportamentos diferenciados, apresentando padrões repetitivos quando interagem com o mundo, além de mostrarem introversão, na maioria dos casos. Então, na tentativa de identificar se era possível fazer uma hipótese diagnóstica, prévia ao diagnóstico, não necessariamente feito por um especialista, foi desenvolvido um modelo de classificação binária para tentar classificar esses indivíduos de acordo com a presença dessa condição: autista ou não-autista.
Tipo de problema:
Imagem 2 - imagem relacionado a um modelo de classificação binário ok

Como o nosso objetivo foi classificar os indivíduos pela presença dessa condição, é preciso escolher algorítimos que podem encontrar um padrão dentro dessa amostra. O próprio objetivo já remete o tipo de problema que é preciso resolver, que é o de classificação.
Classificação é um problema que cobre os algoritmos de aprendizagem de máquina, que trabalham com conjuntos de dados rotulados, ou seja, já possuem previamente o resultado. Num conjunto de dados para problema de classificação, as variáveis que possuem características e a variável resposta (rótulo de classificação) fazem parte do mesmo conjunto de dados a serem observados. Isso permite treinar o modelo de classificação para que posteriormente seja possível inferir a classe esperada de indivíduos ainda não observados.
Os modelos de classificação podem ser simples (binários) ou mais complexos (multi-classe), neste modelo específico o conjunto de dados que foi adquirido no repositório UCI repository é de classificação binária onde está presente apenas duas classes, que confirma a presença e ausência do autismo nos pacientes.
Seleção de Variáveis
Um dos maiores desafios na construção de modelos preditivos é saber escolher as variáveis que serão incluídas. Pensando nisso foi proposto a utilização de uma matriz de correlação, que nos permite observar como as variáveis estão correlacionadas entre si.
A correlação pode ajudar a descobrir se existem variáveis que prejudicam nossa modelagem, pois a partir do momento que duas variáveis possuem alta correlação para o modelo isso significa a presença de duas variáveis com a mesma informação, em contrapartida variáveis com baixa correlação nos informa que elas são independentes entre si e informam coisas distintas. Abaixo, segue a matriz de correlação utilizada.
imagem 4 - Imagem da matriz de correlação das variáveis. ok
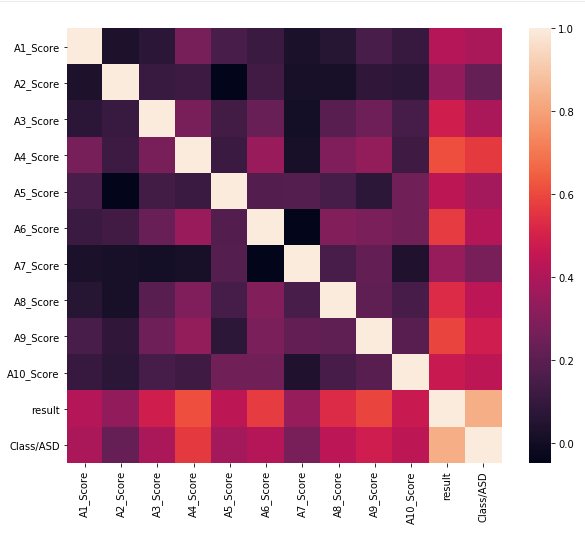
Tendo em mãos a matriz de correlação é possível observar alguns pontos:
- As variáveis de traços comportamentais A1 Score à A10 Score estão pouco correlacionadas.
- A variável result mostra uma alta correlação.
Então, a partir desses pontos analisados podemos concluir que as variáveis de traços comportamentais são viáveis, entretanto a variável result é extremamente enviesada, ou seja, pode levar o algoritmo a aprender a amostra ao invés de generalizar a população.
Tipo de modelo
Levando em conta o tipo de problema e alguns outros pontos que serão explicados posteriormente nos comete então a escolha do método de árvore de decisão.
O que seria um modelo de árvore de decisão?
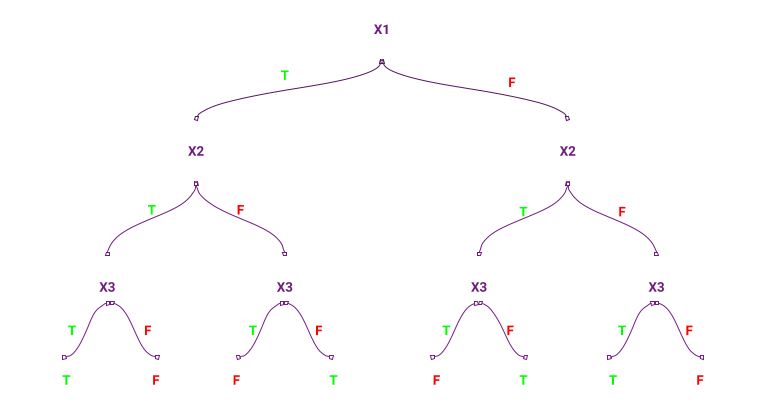
Modelagem
Performance do modelo
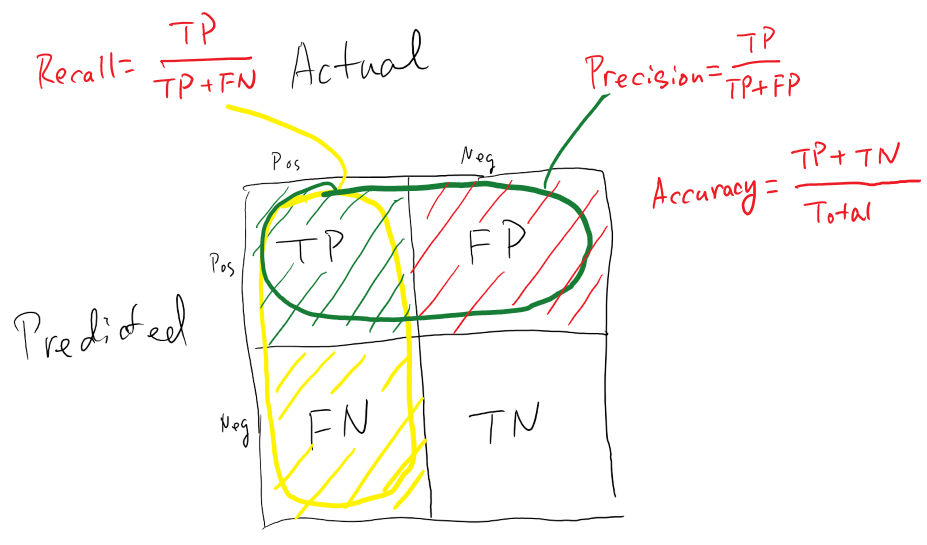
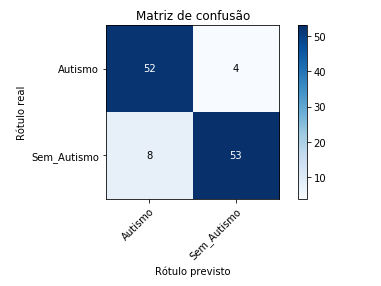
Avaliar um modelo e verificar se ele realmente está se comportando como foi proposto é imprescindível. Partindo desse ponto, dado que o tipo de problema é de classificação, será então utilizado uma matriz de confusão que será executada sobre uma amostra de teste não-observada anteriormente para obter métricas de classificação e estimar a performance esperada do modelo.
A matriz de confusão gerada pelo modelo, pode ser visualizada logo abaixo.
Importância das variáveis ( Feature importance)
Para entender como o modelo desenvolvido interpretou o problema, é preciso entender quais foram as variáveis que tiveram maior importância. Abaixo, segue o gráfico que contém essas importâncias.
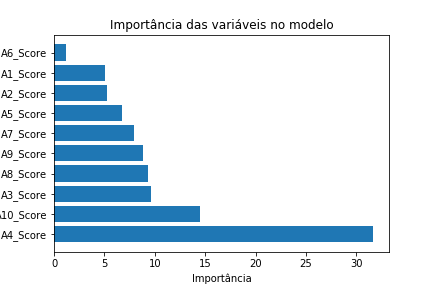
De acordo com o gráfico, os traços comportamentais A4 e A10 tiveram maior influência na decisão do modelo para classificar os pacientes. Esses traços estam relacionados a facilidade de realizar inúmeras tarefas simultaneamente e dificuldade de fazer novas amizades, respectivamente A4 e A10.
Com base nisso, é possível ter uma noção de que o modelo está se baseando de forma sensata em atributos que fazem sentido, pois quando é mostrado que a facilidade de realizar inúmeras tarefas é importante na classificação, o modelo não necessariamente está dizendo que quem tem essa facilidade é autista, é no sentido de ausência desse traço comportamental que representa a presença do autismo. Já no de dificuldade de fazer novas amizades é previsivel que isso tenha certa relevância, pois é algo que caracteriza alguém com autismo em diversas literaturas.